This article is part of a series where I discuss dn42, a decentralized VPN and community for studying network technologies. You can find out more about dn42 on its Wiki: https://dn42.dev/
All of my examples here use Bird 2, and assume you use the same config variables as dn42's guide: https://dn42.dev/howto/Bird2
Multiple servers on dn42: iBGP and IGPs
Connecting to dn42 is fairly straightforward - after registering your resources, you coordinate with other participants to establish tunnels onto the network. However, dn42 is more than just adding peers. At some point, you may want to expand your own network to multiple machines and locations.
Before you can setup peerings from multiple locations though, your nodes first need to have a complete picture of your own network. In addition to all your external BGP connections, this requires configuring another another piece: internal BGP, or iBGP for short.
An iBGP example
NOTE: only use this example if you do not have an IGP already set up in your network - otherwise scroll down to the "Refactored iBGP example" section!
protocol bgp ibgp_node2 {
local as OWNAS;
neighbor fd86:bad:11b7::1 as OWNAS;
direct;
ipv4 {
next hop self;
# Optional cost, e.g. based off latency
cost 50;
import all;
export all;
};
ipv6 {
next hop self;
cost 50;
import all;
export all;
};
}At first glance, iBGP looks very similar to an external BGP session. The major difference is in that iBGP, the peer AS is the same as your own.
In the simplest configuration, iBGP must be configured in a full mesh between all routers. iBGP links do not automatically share routes received from other peers, so missing a connection here will cause routes to go missing on some nodes.
As simple as this seems, there are some important pieces to the config here:
direct;specifies that the neighbour is directly connected.- By default, Bird assumes external BGP peers are directly connected, but that iBGP peers are connected in multihop mode.
- In multihop mode, the target IP of the neighbour is not directly attached to an interface, but routed towards you by some other means (more on this later)
next hop self;tells Bird to rewrite next hops in routes when exporting them to iBGP neighbours.- By default, the next hop of routes received from eBGP neighbours is preserved when sending them to an iBGP peer.
- In the below example, Router A receives a route for 10.0.1.0/24 from the neighbour AS, with a next hop of 10.0.1.3. When router B receives this route over iBGP without
next hop self, it tries to add the route with the same next hop (10.0.1.3) - But no interface has that IP on router B, because the neighbour AS is only connected to router A. This causes the route export to fail… The fix here, of course, is to add
next hop self;so that the route points to router A instead (which will forward traffic onto the neighbour).
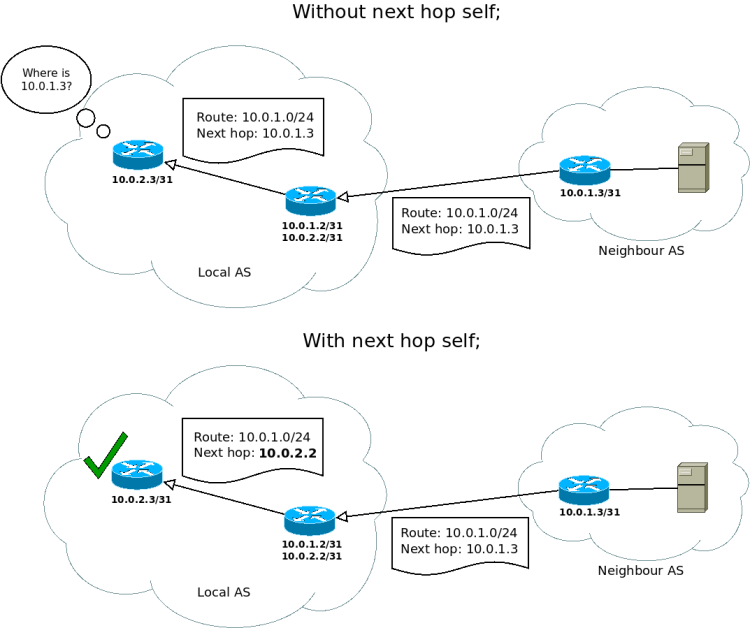
You might be wondering, why do the defaults for iBGP already differ so much from this configuration? The answer is that BGP expects that you use an interior gateway protocol (IGP) in addition to iBGP to manage routes within your network.
Interior Gateway Protocols (IGPs)
What is an IGP? Whereas BGP is designed to route traffic between networks (i.e. between autonomous systems), IGPs are designed to route traffic internally within a network. There are many IGP implementations - in this page, I'll focus on OSPF v3 and Babel, which are two (IPv6-ready!) protocols natively supported by Bird.
Structurally, these are quite different from BGP:
- BGP configures neighbours based on AS number and IP, whereas IGP neighbours are based off interfaces and their associated prefixes
- iBGP requires configuring routers in a full mesh (or in a hub-spoke topology using route reflectors), while IGPs can adapt to any topology
- BGP chooses best paths through its own set of rules, while OSPF and Babel prefer the shortest path based off link costs (equal to fewest hops if no costs are configured).
IGP redundancy and loopback/dummy interfaces
Although IGPs do not require a full mesh between links, having multiple paths between targets adds redundancy to your network. If one such path goes down, IGPs react fast enough that TCP connections like SSH and BGP are uninterrupted.
This fast failover provides great benefits to BGP, and it’s why iBGP sessions are set to multihop by default. If a BGP session is configured against a directly connected neighbour, and the connection to that neighbour goes down, the BGP session goes down with it. Running BGP in multihop mode means that connections to the neighbour can automtically failover to redundant routes provided by your IGP when needed.
Hans van Kranenburg has a set of networking lab exercises which covers OSPF and explains this behaviour in detail: https://github.com/knorrie/network-examples/tree/master/ospf-intro#more-dynamics
(graphic borrowed from the above link)
To send routes for BGP peering IPs through an IGP, they should be attached to an interface. This can be done by creating a loopback or dummy interface. On Linux, which one you use doesn’t make any major difference, though I prefer using a dummy interface because it creates a logical separation between default loopback IPs and those specific for dn42.
Here's an example using Debian's ifupdown (interfaces(5)) config:
iface igp-dummy0 inet static
address 172.20.229.113
netmask 255.255.255.255
network 172.20.229.113
pre-up ip link add igp-dummy0 type dummy
iface igp-dummy0 inet6 static
address fd86:bad:11b7::1/128In my configuration, I set up the public dn42 IPs of my servers in loopback. This means that the IPs used in the VPN tunnels between nodes have to be something different. For those, I used link-local v6 addresses instead and IPv4 addresses in the 192.168.x.x range.
IGP example: OSPF
OSPF is a well-established and widely supported routing protocol. There are two versions actively in use, OSPF v2, which is IPv4 only, and OSPF v3, which supports both IPv4 and IPv6. OSPF v3 runs over link local IPv6 addresses using its own protocol type: protocol number 89.
OSPF is fairly complex, but also very feature complete. A core feature it provides is areas, which group routers into logical subdivisions and hide their details from each other. On larger networks, this saves a lot of resources by reducing the amount of routes each router has to keep track of.
For a small dn42 network, it's most likely fine to stick to the backbone area (area 0).
Note: Bird requires two sessions to run both IPv4 and IPv6 in OSPFv3. It can thus be helpful to configure areas in a separate file and use include statements.
/etc/bird/ospf.conf:
protocol ospf v3 int_ospf {
ipv4 {
# Only route our internal network using OSPF - ignore
# everything sent from BGP. (I'll mention why in detail later)
import where is_self_net() && source != RTS_BGP;
export where is_self_net() && source != RTS_BGP;
};
include "/etc/bird/ospf_backbone.conf";
};
protocol ospf v3 int_ospf6 {
ipv6 {
import where is_self_net_v6() && source != RTS_BGP;
export where is_self_net_v6() && source != RTS_BGP;
};
include "/etc/bird/ospf_backbone.conf";
};/etc/bird/ospf_backbone.conf:
area 0 {
# Wildcards are supported in interface names, though defining them separately
# gives you more flexibility in costs.
interface "igp-nodeABC" {
cost 123;
};
interface "igp-nodeDEF" {
cost 88;
};
# Loopback interface on each machine
interface "igp-dummy*" {
# Marking an interface as stub tells Bird to not send OSPF traffic to it,
# but still route the prefixes associated with it to other peers.
stub;
};
};IGP example: Babel
Babel is a simple and modern protocol designed to work with minimal configuration. It supports both IPv4 and IPv6, and runs over link-local IPv6 on UDP port 6696. However, Babel is comparably new and not as widely supported as OSPF.
Two software implementations for Babel exist: the reference implementation babeld and the one in Bird. babeld adds some extension features such as generating automated cost metrics based off latency. It's possible to combine it with Bird by having Bird learn routes from the kernel routing table, but this is not something I've tested yet. In this example, I use Bird's implementation with some manually configured costs:
/etc/bird/babel.conf:
# Babel does not have the concept of stub areas. Instead, we should use Bird's
# "direct" protocol to read prefixes attached to interfaces and send them across
# the network.
protocol direct {
ipv4;
ipv6;
interface "igp-dummy*";
};
protocol babel int_babel {
ipv4 {
import where source != RTS_BGP && is_self_net();
export where source != RTS_BGP && is_self_net();
};
ipv6 {
import where source != RTS_BGP && is_self_net_v6();
export where source != RTS_BGP && is_self_net_v6();
};
interface "igp-nodeABC" {
# Note: Babel's cost metric is slightly different from BGP and OSPF.
# rxcost specifies the cost for the neighbour to send traffic to us,
# not the cost to send TO that neighbour. Of course, this won't have
# any impact if you keep costs consistent on both ends.
rxcost 123;
};
interface "igp-nodeDEF" {
rxcost 88;
};
};Refactored iBGP example
Once you have an IGP configured in your network, a configuration for running iBGP on top of your IGP would look something like this:
In particular, the direct and cost directives have been removed. The target neighbour IP is exactly the same, but here its prefix is being routed by your IGP, and iBGP can operate in the default multihop mode.
protocol bgp ibgp_node2 {
local as OWNAS;
neighbor fd86:bad:11b7::1 as OWNAS;
ipv4 {
import where source = RTS_BGP && is_valid_network() && !is_self_net();
export where source = RTS_BGP && is_valid_network() && !is_self_net();
next hop self;
};
ipv6 {
import where source = RTS_BGP && is_valid_network_v6() && !is_self_net_v6();
export where source = RTS_BGP && is_valid_network_v6() && !is_self_net_v6();
next hop self;
};
}IMPORTANT: In these examples, I’ve set filters to clearly separate BGP and non-BGP routes within your network. This is especially important, because having an IGP and iBGP both send the same routes will lead to unpredictable behaviour. Specifically:
- If you send BGP routes over an IGP, all BGP-specific information such as AS path length will get stripped. Then when these routes get advertised to other BGP neighbours, you will be hijacking other networks!
- If you send routes from your IGP over BGP, the results aren't as disastrous but still not ideal.
- Bird in particular does not seem to support this case well: Section 2.1 of the manual says that "The global best route selection algorithm is (roughly) as follows: ... If source protocols are different (e.g. BGP vs. OSPF), result of the algorithm is undefined.".
- Other vendors treat this case differently: e.g. see the "BGP redistribution" section of this Noction article about BGP and OSPF.
- Either way, I would recommend against doing this because it sends redundant routes to your BGP peers. Normally, your network ranges are sent as blocks to your peers (IPv4 /27, IPv6 /48, etc.). When passing IGP routes to BGP, you end up sending more specific routes for each IP in your network, even though they are not needed. (Obviously this will become a problem if your network grows, because you'll be sending BGP updates for a lot of IPs!)
Note 2: when using an IGP, whether you want to use next hop self is a design choice. Although OSPF and Babel will have no problem routing the interfaces created for your peers, you may want to keep your IGP cleaner by only including prefixes that are actually yours. If you wish, you could instead add whatever interface pattern matches your dn42 peers to your IGP and remove the next hop self option.
Note 3: Because our IGP already configures costs between links, it's not necessary to configure them here too. Bird will automatically read OSPF metrics between links when computing the internal cost to a boundary router. For Babel, support for this got added in Bird v2.0.8.
What to use?
In this post, I've outlined 3 possibilities for designing your network: pure iBGP, OSPF, and Babel.
The main advantage that IGPs offer is the ability to failover BGP connections to indirect paths if a direct connection goes down. But, there's a case to be made too for a simpler network configuration using only one protocol.
My advice? Try more than one and find what works best for you.
| Pure BGP | OSPF | Babel | |
|---|---|---|---|
| Pros |
|
|
|
| Cons |
|
|
|